2024. 2. 1. 16:50ㆍpython/intermediate
연구, 교육 및 학습 활동을 문서화하고 공유하는 데 사용할 수 있는 도구 키트인 JupyterLab을 사용하면 더 많은 것을 성취할 수 있습니다 . 데이터 분석 및 데이터 시각화부터 과학 연구에 이르기까지 광범위한 분야에서 유용합니다.
JupyterLab은 여러 노트북을 효과적으로 함께 사용할 수 있는 브라우저 기반 인터페이스를 제공하여 노트북을 향상시킵니다 . 또한 포괄적인 Markdown 편집기, 파일 관리자, 파일 뷰어 및 광범위한 파일에서 코드를 실행할 수 있는 인프라를 제공합니다.
이 튜토리얼에서는 다음 방법을 배웁니다.
여러 Jupyter 노트북 간에 코드 공유 Jupyter 노트북 디버깅 마크다운 파일 생성 및 관리 다양한 파일에서 포함된 코드 실행 단일 인터페이스에서 다양한 파일 형식을 관리하고 봅니다. JupyterLab 내에서 운영 체제에 액세스하세요. Jupyter 는 세 가지 프로그래밍 언어인 Ju lia, Py thon 및 R이 혼합된 합성어 입니다 . 이 자습서에서는 Python에 중점을 두지만 다른 언어에서도 Jupyter를 사용할 수 있습니다. 또한 이 무료 애플리케이션은 macOS, Linux 및 Windows 환경에서 작동합니다.
JupyterLab은 Jupyter Notebook 사용을 다른 수준으로 끌어올리므로 Jupyter Notebook에 이미 익숙하다면 이 자습서를 최대한 활용할 수 있습니다.
JupyterLab 설치 및 시작
JupyterLab을 컴퓨터에 설치하는 가장 깔끔한 방법은 가상 환경을 사용하는 것입니다 . 이렇게 하면 JupyterLab 작업이 이미 보유하고 있는 다른 Python 프로젝트나 환경을 방해하지 않게 됩니다. 이 자습서에서는 이라는 새 가상 환경을 만듭니다.
JupyterLab을 설치하려면 터미널을 실행하고 다음 명령을 실행하십시오.
# terminal
$ mkdir jupyterlab
$ cd jupyterlab
$ python3 -m venv venv
$ source venv/bin/activate
(venv) $ python -m pip install jupyterlab
jupyterlab을 깔끔하게 유지하려면 먼저 모든 JupyterLab 작업을 위한 새 디렉터리를 만듭니다 . 나중에 각 프로젝트에 대해 개별 하위 디렉터리를 만들어 정리된 상태로 유지할 수 있습니다.
이제 터미널 프롬프트에 (venv)활성 환경이 표시됩니다. 즉, 이 시점부터 수행하는 모든 작업은 이 환경에서 발생하며 다른 곳에서 수행할 수 있는 다른 Python 작업과 별도로 유지됩니다.
마지막으로 깔끔함을 위해 이름이 지정된 새 디렉터리를 만든 tutorial_project다음 그 안에서 JupyterLab을 시작합니다.
# terminal
(venv) $ mkdir tutorial_project
(venv) $ cd tutorial_project
(venv) $ jupyter lab
JupyterLab이 웹 브라우저에서 시작되어 사용할 준비가 모두 완료됩니다. 하지만 시작하기 전에 세션을 종료하는 방법을 알고 싶을 수도 있습니다.
- JupyterLab을 종료하려면 모든 내용이 저장되었는지 확인한 다음 브라우저를 닫기 전에 파일 → 종료를 사용하여 애플리케이션을 닫습니다. 그러면 모든 것이 깔끔하게 종료됩니다. 브라우저를 닫는 것만으로는 서버가 닫히지 않으며, 서버가 충돌하면 데이터가 손실될 수 있습니다.
- 다시 시작하려면 Powershell이나 터미널을 열고 jupyterlab_projects폴더로 이동한 다음 을 활성화하세요 jl_venv. 마지막으로 특정 프로젝트의 폴더를 생성하거나 입력한 다음 이전과 같이 JupyterLab을 시작합니다.
- 가상 환경을 비활성화하려면 다음 deactivate명령을 사용하십시오. 명령 프롬프트가 정상으로 돌아갑니다.
JupyterLab을 설치하고 시작하면 웹 브라우저 연결과 함께 서버가 시작됩니다. 잠시 시간이 걸릴 수 있지만 곧 기본 인터페이스를 보게 될 것입니다.
JupyterLab 커널 이해
JupyterLab의 도구는 귀하의 작업을 지원합니다. 도구는 독립적이지만 일부 도구를 함께 사용하면 더 많은 것을 얻을 수 있습니다. 이 통합은 아마도 JupyterLab의 가장 강력한 기능일 것입니다.
JupyterLab을 배울 때 좋은 출발점은 JupyterLab의 기본 구성 요소가 무엇인지, 그리고 이들을 함께 작동시키는 방법을 아는 것입니다. 아래 다이어그램은 이에 대한 개요를 보여줍니다.

이 다이어그램은 여러 부분으로 구성되어 있기 때문에 처음에는 부담스러워 보일 수 있습니다. 걱정하지 마십시오. 곧 관련성을 알게 될 것입니다. 화살표는 다양한 구성 요소가 상호 작용하는 방식을 보여줍니다. 이러한 상호 작용은 JupyterLab의 큰 이점 중 하나입니다. 애플리케이션과 다이어그램의 중심 부분인 커널부터 시작합니다.
JupyterLab 설치에서 가장 중요한 구성 요소는 커널입니다. 이전 다이어그램에서 볼 수 있듯이 이는 애플리케이션의 핵심입니다. 새로운 Jupyter Notebook 또는 콘솔을 시작할 때마다 다음과 같은 버튼을 클릭합니다.
버튼을 클릭하면 JupyterLab 커널 인스턴스가 시작됩니다 . 이는 파일을 콘솔 에 연결하는 프로세스입니다 . 파일은 노트북, Python 파일, Markdown 파일 또는 텍스트 파일과 같은 코드가 포함된 모든 파일일 수 있습니다. 커널 은 파일의 프로그래밍 코드를 콘솔로 전달 합니다 . 그러면 콘솔이 코드를 실행하고 출력을 표시합니다. Jupyter Notebook의 경우 출력은 노트북 자체에 표시됩니다.
참고: JupyterLab의 맥락에서 커널에 대해 읽을 때마다 이는 파일을 콘솔에 연결하는 프로세스를 의미합니다. 컴퓨팅에서 커널이라는 단어는 일반적으로 하드웨어와 상호 작용할 수 있는 컴퓨터 운영 체제의 핵심을 나타냅니다. 이는 여기서 사용할 커널과는 아무런 관련이 없으므로 이러한 다른 의미를 혼동하지 마십시오.
Jupyter Notebook을 열면 해당 커널이 자동으로 열립니다. 이것이 바로 내부에서 코드를 즉시 실행할 수 있는 이유입니다. 나중에 배우게 되겠지만 커널을 사용하면 Markdown 파일과 같은 다른 파일 형식에 포함된 코드를 실행할 수도 있습니다 . 아래 스크린샷은 열려 있는 문서 중 일부를 보여주며, 그 중 일부는 커널을 사용하고 있습니다.
출력을 주의 깊게 살펴보면 상단 부분에 5개의 열린 탭이 있는 것을 볼 수 있습니다.
- Untitled8.ipynb, 커널에 자동으로 할당된 Jupyter Notebook입니다.
- Console5, 커널에 자동으로 할당된 콘솔입니다.
- untitled4.md커널이 할당되지 않은 파일입니다 . 이 Markdown 파일에는 코드가 포함될 수 있지만 실행할 수는 없습니다.
- untitled5.md콘솔이 할당되어 있으므로 커널도 할당된 파일입니다 . 이 Markdown 파일에 포함된 코드를 실행할 수 있습니다.
이 튜토리얼의 나머지 부분을 진행하면서 커널이 얼마나 중요한지 알게 될 것입니다.
JupyterLab에서 Jupyter Notebook 작업
이 튜토리얼은 Jupyter Notebook 전용 튜토리얼은 아니지만 이제 JupyterLab이 Jupyter Notebook에 제공하는 기능을 이해할 수 있도록 몇 가지 일반적인 작업을 수행하게 됩니다. 다음과 같이 노트북 제목 아래에 있는 큰 Python 3 버튼을 클릭하여 JupyterLab 내에서 새 Jupyter 노트북을 시작합니다.

그러면 이름이 붙은 새로운 Jupyter Notebook이 열립니다 Untitled.ipynb. 좀 더 설명적인 이름을 지정하고 싶을 가능성이 높으며 탭을 마우스 오른쪽 버튼으로 클릭하고 노트북 이름 바꾸기… 를 선택한 다음 이름을 좀 더 의미 있는 이름으로 변경하면 됩니다. 이 예에서는 이름을 Population Data으로 바꾸도록 선택합니다.
이름을 입력한 후 파란색 이름 바꾸기 버튼을 클릭하여 노트북을 새 이름으로 업데이트하세요.
새 전자 필기장을 열면 단일 회색 직사각형이 포함됩니다. 이는 위에 있는 도구 모음 툴바의 드롭다운 옵션에 표시된 코드 텍스트로 표시되는 코드 셀 입니다. 여기에 프로그램 코드를 입력한다는 사실을 알면 놀라지 않을 것입니다. 일반적으로 노트북을 만들 때 서식이 지정된 마크다운 텍스트를 소개로 시작하고 싶을 것입니다.
Markdown을 만들려면 코드 셀을 선택한 다음 도구 모음의 드롭다운 메뉴에서 Markdown을 선택하세요. 그러면 Markdown 텍스트를 입력할 셀이 준비됩니다. 이제 이 셀에 다음 Markdown 텍스트를 입력하세요.
# 마크다운 텍스트
### Changes in World Population Since 1960
The data shown below shows how the
[world's population](https://www.worldometers.info/world-population/world-population-by-year/)
has more than doubled since 1960.
This has [implications](https://ugc.berkeley.edu/background-content/population-growth/)
in a variety of areas including:
- Increased extraction of environmental resources.
- Increased fossil fuel usage.
- Increased disease transmission.
- Increased transportation of invasive species.
**The data below shows the population each decade since 1960:**
텍스트를 입력할 때 왜 해시, 별표 및 괄호를 사용했는지 궁금할 것입니다. 알아내는 가장 좋은 방법은 셀을 실행하는 것입니다. 노트북 탭 아래에 있는 오른쪽을 가리키는 작은 삼각형을 클릭하거나 Shift+Enter 사용하여 이 작업을 수행할 수 있습니다 . 어느 쪽이든 셀을 실행하고 Markdown을 화면에 렌더링합니다.

보시다시피 #기호를 사용하여 제목을 지정했으며 기호는 데이터 소스에 대한 하이퍼링크를 만들었습니다. 단일 별표를 사용하여 글머리 기호 목록을 만들었고, 이중 별표를 사용하면 텍스트를 굵게 만들었습니다. 즉, 이러한 문자를 사용하여 출력 형식을 정의했습니다.
Markdown 셀이 올바르게 렌더링되지 않은 경우 해당 셀을 두 번 클릭하여 수정할 수 있습니다. 오류를 변경한 후 다시 실행하면 올바르게 렌더링됩니다. 각 기호는 결과가 어떻게 보이는지에 상당한 차이를 가져온다는 점을 기억하십시오.
Markdown 셀 아래에 새로운 코드 셀이 나타나는 것을 눈치챘을 수도 있습니다. 그런 다음 다음 코드를 추가합니다.
decades = [1960, 1970, 1980, 1990, 2000, 2010, 2020]
# World population (billions)
population = [3, 3.7, 4.4, 5.3, 6.1, 7.0, 7.8]
인구 데이터를 두 개의 Python 목록으로 입력했습니다. 첫 번째 목록에는 수십 년이 포함되고, 두 번째 목록에는 각 10년에 대한 세계 인구가 포함됩니다. Shift+Enter를 사용하여 셀을 실행하면 코드가 실행되고 서식이 지정됩니다.
이 셀을 실행하면 출력이 생성되지 않지만 목록을 설정하고 해당 변수에 할당하므로 실행하는 것이 여전히 중요합니다. 즉, 노트북의 커널이 이를 인식하게 됩니다. 즉, 노트북의 후속 셀에서 변수를 사용할 수 있게 되며, 이 노트북의 커널을 공유하는 경우 다른 노트북에서도 사용할 수 있게 됩니다.
데이터 자체도 의미가 있지만 차트로 표시하면 더 놀랍지 않을까요? 다행히 Matplotlib 라이브러리를 사용하면 이 작업을 수행할 수 있습니다. 모든 타사 라이브러리와 마찬가지로 Python 표준 라이브러리의 일부가 아니기 때문에 Python 환경에 matplotlib를 설치해야 합니다 .
노트북 인터페이스를 사용하면 터미널로 전환할 필요 없이 코드 셀에서 직접 현재 Python 환경에 타사 패키지를 설치할 수 있습니다. 느낌표( !)를 앞에 붙이면 코드 셀에서 셸 명령을 실행할 수 있습니다.
따라서 matplotlib 라이브러리를 설치하려면 새 코드 셀에 !python -m pip install matplotlib을 입력 하고 실행하면 됩니다. 옆에 [*]이 나타나면 코드 셀이 실행되고 있는 것입니다. 설치가 완료되면 대괄호 안의 숫자로 변경됩니다. 이 숫자는 특정 코드 셀이 실행된 순서를 나타냅니다.
명령이 완료되면 일부 설치 출력이 표시됩니다.

보시다시피, pip 명령 출력 아래에 새로운 코드 셀이 나타났습니다. 출력의 마지막 줄을 읽으면 설치가 성공했는지 확인할 수 있습니다. 그런 다음 !python -m pip install matplotlib 명령이 포함된 셀을 선택하고 그림과 같이 휴지통 아이콘을 클릭하여 노트북을 정리할 수 있습니다.
이제 데이터를 차트에 표시합니다. 이렇게 하려면 새 코드 셀에 다음 코드를 입력하고 실행합니다.
from matplotlib import pyplot as plt
plt.plot(decades, population)
plt.xlabel("Year") plt.ylabel("Population (Billion)") plt.title("World Population")
plt.show()
우선, pyplot 블러 들입니다. 이를 통해 플롯을 관리하는 데 사용하는 일련의 기능에 액세스할 수 있습니다. 예를 들어 pyplot의 plot() 기능을 사용하여 기본 플롯을 만듭니다. 또한 함수를 사용하여 각 축의 레이블을 정의하고 차트 제목을 지정합니다. 위의 코드를 새 코드 셀에 입력하고 실행하면 데이터가 차트로 표시됩니다.

데모용으로 간단한 차트를 만들었지만 Matplotlib 의 기능을 사용하여 원하는 방식으로 차트를 추가로 사용자 정의할 수 있습니다 . 결국 노트북은 다른 프로그래밍 프로젝트에서 이미 익숙할 수 있는 동일한 Matplotlib 라이브러리를 사용하고 있습니다.
이제 더 이상 모든 데이터를 분석하지 않기로 결정했다고 가정해 보겠습니다. 대신 1980년 이후의 인구 데이터에 관심이 있습니다. 데이터를 업데이트하고 셀을 다시 실행하기만 하면 됩니다.
아래 표시된 코드로 원본 셀을 업데이트하세요. 나중에 원본 데이터로 돌아가고 싶은 경우를 대비해 원본 데이터를 주석 처리할 수 있습니다.
# decades = [1960, 1970, 1980, 1990, 2000, 2010, 2020]
# World population (billions)
# population = [3, 3.7, 4.4, 5.3, 6.1, 7.0, 7.8]
decades = [1980, 1990, 2000, 2010, 2020]
population = [4.4, 5.3, 6.1, 7.0, 7.8]
변경한 후에는 셀을 다시 실행하여 decades및 population목록 변수의 내용을 업데이트하세요. 그런 다음 차트를 업데이트하려면 차트 코드가 포함된 셀을 다시 실행하세요. 이를 통해 차트가 업데이트되었으며 이제 다음과 같이 표시됩니다.
from matplotlib import pyplot as plt
plt.plot(decades, population)
plt.xlabel("Year")
plt.ylabel("Population (Billion)")
plt.title("World Population")
plt.show()
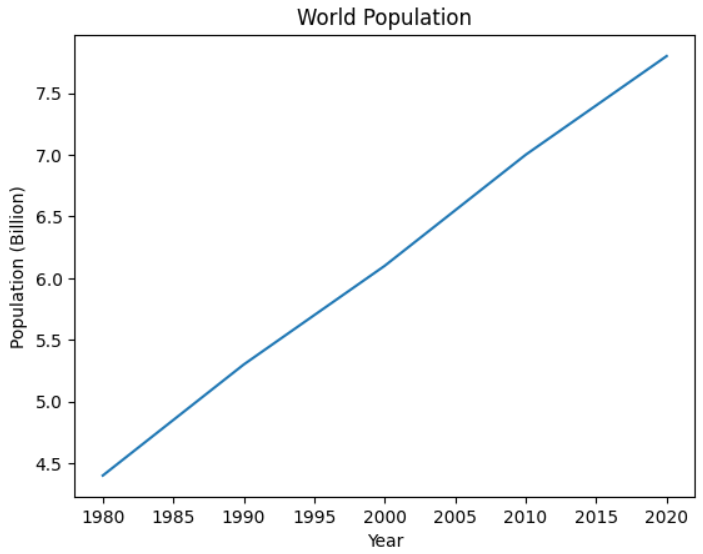
보시다시피 이제 1980년부터 2020년까지만 차트에 표시됩니다.
앞서 JupyterLab에는 Jupyter Notebook을 향상하는 기능이 포함되어 있다는 것을 배웠습니다. 이제 여러분이 이것을 실제로 볼 시간입니다.
여러 노트북 작업
다음으로 JupyterLab이 여러 노트북으로 작업하는 데 어떻게 도움이 되는지 알아봅니다. 물론 이렇게 하려면 다른 노트북을 만들어야 합니다.
Population Data노트북을 열어두고 두 번째 노트북을 열어 보세요 . 이렇게 하려면 새 실행기 '+' 탭을 클릭하세요. 이제 노트북 제목 아래에 있는 Python 3 아이콘을 클릭하여 다른 노트북을 시작하세요 . 두 번째 노트북이 자체 탭에서 시작됩니다. 이 탭을 마우스 오른쪽 버튼으로 클릭하고 노트북 이름을 Population Changes으로 바꿉니다.

보시다시피 노트북 탭은 나란히 배치되어 있습니다. 전문적으로 보이도록 하려면 Population Changes 노트북의 의도된 내용에 대해 약간 설명하는 Markdown을 추가하는 것이 좋습니다.
# 마크다운 텍스트
### Population Changes Since 1980
The data shown below shows the decade-on-decade increases in the [world's population](https://www.worldometers.info/world-population/world-population-by-year/) since 1980.
Shift+Enter를 사용하여 Markdown 셀을 실행하여 셀에 렌더링하는 것을 잊지 마십시오.
현재 노트북 배열에서는 탭을 클릭하여 노트북 사이를 쉽게 이동할 수 있지만 이 두 번째 노트북을 사용하여 세계 인구 데이터를 분석한다고 가정해 보겠습니다. 가장 먼저 해야 할 일은 통합 Population Data문서의 인구 데이터를 추가하는 것입니다. 물론 복사하여 붙여넣을 수도 있지만 JupyterLab을 사용하면 두 노트북을 동시에 볼 수 있는 경우 여러 노트북 간에 직접 셀을 드래그할 수 있습니다.
노트북을 나란히 표시하려면 Population Changes 노트북 탭을 Population Data 노트북 오른쪽 아래로 드래그했습니다. 마우스를 놓으면 두 통합 문서가 모두 표시됩니다.
그런 다음 Notebook 간에 셀을 복사하기 위해 Population Data의 decades 및 population 목록이 포함된 셀을 선택했습니다. 셀 오른쪽에 파란색 세로 막대가 나타나면 해당 항목을 선택한 것입니다.
마지막으로 그림과 같이 여백 영역을 잡고 끌어서 Population Changes 위에 놓았습니다. 배치 가이드로 나타나는 가는 파란색 가로선을 사용했습니다.
참고: 셀을 잘못된 위치로 이동한 경우 해당 셀을 선택하고 수직으로 원하는 위치로 드래그하세요. 또한 Population Changes 노트북을 원래 위치로 다시 이동하려면 탭을 원래 있던 탭 Population Data옆으로 다시 드래그하세요.
노트북에 Python 라이브러리 추가
다음으로 Population Changes 노트북을 분석하겠습니다. 이렇게 하려면 코드를 더 추가하고 pandas 라이브러리를 가져와야 합니다.
방금 복사한 셀 바로 아래의 코드 셀에 다음 코드를 추가합니다.
def calculate_differences(data_set):
differences = [0]
for index in range(1, len(data_set)):
differences.append(round(data_set[index] - data_set[index - 1], 1))
return differences
population_change = calculate_differences(population)
calculate_differences() 함수는 숫자 목록을 받아들이고 각 요소 간의 차이를 계산합니다. 이러한 차이점은 별도의 목록으로 반환됩니다. 코드의 마지막 줄은 함수를 호출하고 셀을 실행할 때 반환된 목록을 저장합니다. 아무것도 표시되지 않습니다.
더 진행하기 전에 이 셀을 실행하여 내용이 기본 커널에 알려졌는지 확인하세요.
다음으로 pandas DataFrame 을 만듭니다. Pandas DataFrame에 데이터를 저장하면 이에 대한 많은 데이터 분석을 수행할 수 있습니다. 여기서는 데이터가 포함된 깔끔한 테이블을 선택하게 됩니다.
pandas는 기본 Python 언어의 일부가 아닌 또 다른 모듈 이므로 설치해야 합니다. 이렇게 하려면 새 코드 셀을 추가하고 !python -m pip install pandas을 입력합니다. 셀을 실행하면 팬더가 설치됩니다. 설치 오류가 없는지 확인하려면 출력의 마지막 줄을 확인하십시오.
참고: Pandas 모듈은 실제로 각 노트북을 구동하는 기본 Python 프로그래밍 환경 또는 가상 환경에 설치되었습니다. 즉, pip다른 노트북에서 명령을 다시 실행하는 대신 import pandas만 하면 됩니다. 또한 다음에 JupyterLab을 다시 시작해도 Pandas는 그대로 유지됩니다.
Pandas를 성공적으로 설치한 후에는 이를 사용하여 원하는 방식으로 데이터를 분석할 수 있습니다. 여기서는 DataFrame만 필요하므로 노트북의 코드 셀에 다음 코드를 추가하세요.
!python -m pip install pandas
import pandas as pd
zipped = list(zip(decades, population, population_change))
columns=["Decade", "Population(Bn)", "Change"]
population_df = pd.DataFrame(zipped, columns=columns)
print(population_df)
방금 설치한 pandas 모듈을 사용하려면 이를 가져와야 합니다. 그런 다음 Python의 내장 zip함수를 사용하여 각 목록을 병렬로 반복하고 각 목록의 항목이 포함된 튜플 컬렉션을 생성합니다. 그런 다음 해당 컬렉션을 pandas DataFrame 생성자에 전달하여 DataFrame을 생성합니다. 또한 columns매개변수를 사용하여 DataFrame의 열을 지정합니다.
셀을 실행하면 볼 수 있듯이 DataFrame은 깔끔한 테이블로 표시됩니다.

뷰 살펴보기
긴 파일이 있는 경우 관심 있는 내용을 보려면 아래로 스크롤해야 할 수도 있습니다. 이를 극복하기 위해 JupyterLab에서는 파일에 대한 여러 개의 동기화된 보기를 생성할 수 있습니다. 노트북과 같은 파일에 새 보기를 만들면 해당 파일에 액세스하기 위한 새 인터페이스가 만들어집니다. 각 보기를 사용하면 파일의 개별 부분을 동시에 볼 수 있습니다. 게다가 노트북을 변경하면 해당 보기도 업데이트됩니다.
노트북 외부에서 Matplotlib 차트를 보고 싶다고 가정해 보겠습니다. 이렇게 하려면 자체 탭에 차트의 새 보기를 만듭니다. 그러나 차트는 여전히 기본 노트북 코드에 연결됩니다. 노트북에서 차트의 데이터를 변경하면 노트북과 뷰 모두에서 차트가 업데이트됩니다. 이는 노트북이 길고 노트북의 여러 부분을 동시에 보고 싶을 때 매우 유용합니다.
참고: Markdown 셀의 보기를 만들 수는 없지만 전체 노트북의 보기를 만들어 이 문제를 해결할 수 있습니다. 이렇게 하려면 뷰를 만들려는 통합 문서의 탭을 마우스 오른쪽 버튼으로 클릭하고 노트북용 새 보기 를 선택합니다 . 새 보기가 별도의 탭에 표시됩니다. 그런 다음 원본 노트북과 별도로 보기를 스크롤할 수 있습니다.
Population Data 노트북을 선택한 다음 Matplotlib 코드가 포함된 셀을 선택합니다.

이제 셀이나 기존 차트를 마우스 오른쪽 버튼으로 클릭하고 셀 출력에 대한 새 보기 만들기를 선택합니다 . 노트북 아래에 새로운 보기 탭이 나타납니다. 탭을 드래그 앤 드롭하여 화면 주변의 뷰 위치를 원하는 곳으로 이동할 수 있습니다. 보기는 기본 노트북에서 보고 있는 셀에 관계없이 항상 동일한 콘텐츠를 표시합니다.

보시다시피 새 보기는 해당 보기가 있는 노트북 바로 아래에 나타납니다. 인구 데이터 노트북에 포함된 데이터를 자유롭게 변경하고 해당 셀과 차트가 포함된 셀을 다시 실행하세요. Notebook의 차트를 업데이트하는 것 외에도 보기에서도 업데이트됩니다.
노트북을 닫으면 보기도 닫힙니다. 노트북과 달리 보기는 저장되지 않습니다. 보기만 닫으려면 해당 탭에서 X를 클릭하여 닫으면 됩니다 .
참고: 뷰는 가장 일반적으로 Jupyter Notebook과 연결되어 있지만 실제로는 JupyterLab 내에서 사용 가능한 모든 파일 형식에 뷰를 생성할 수 있습니다. 예를 들어 긴 PDF 파일에 대해 첫 번째 페이지와 마지막 페이지를 모두 볼 수 있는 두 개의 보기를 만들 수 있습니다. 또한 파일의 모든 보기는 동일한 파일을 보기 때문에 한 보기를 통해 변경한 내용은 다른 보기에 반영됩니다.
물론 여러 파일을 여는 것과 결합하여 여러 보기를 만드는 것은 매우 유용할 수 있지만 JupyterLab을 다시 시작할 때마다 모든 것을 다시 열어야 하는 것은 번거로운 일입니다. 다행히도 다음에 볼 수 있듯이 실제로 그럴 필요는 없습니다.
작업공간 작업
JupyterLab 작업 영역 은 열려 있는 노트북 및 터미널과 같은 다양한 구성 요소의 저장된 레이아웃입니다. 기본적으로 JupyterLab은 레이아웃 변경 사항을 자동으로 저장합니다. 이렇게 하면 마지막으로 닫았을 때와 동일한 레이아웃을 계속 사용할 수 있습니다. 여러 세션에 걸쳐 분석을 수행하는 경우 이 기능이 매우 유용하다는 것을 알게 될 것입니다.
자체 파일 세트 또는 기타 구성 요소를 동시에 열어야 하는 여러 프로젝트에서 작업하는 경우 해당 레이아웃을 사용자 정의 작업 영역으로 저장하여 나중에 다시 빠르게 돌아갈 수 있습니다.
작업 영역은 포함된 파일과 화면상의 레이아웃에 대한 정보가 포함된 JSON 파일입니다. 즉, 작업 공간 파일을 삭제해도 해당 파일이 참조하는 파일은 삭제되지 않습니다.
뷰를 포함하여 JupyterLab 세션 콘텐츠의 레이아웃을 저장할 수 있습니다. 이렇게 하려면 작업 공간을 저장합니다. 우선 모든 내용을 저장했는지 확인하세요. "파일 → 모두 저장 메뉴" 옵션을 선택하면 이 작업을 빠르게 수행할 수 있습니다 . 레이아웃을 저장하려면 "파일 → 현재 작업 공간을 다른 이름"으로 저장을 선택한 다음 이름을 population_analysis.jupyterlab-workspace로 주십시요. 파일 브라우저에 작업공간 레이아웃 파일이 추가됩니다.

다음에 JupyterLab을 열면 프로그램을 마지막으로 닫았을 때와 같은 방식으로 모든 것이 표시됩니다. 작업 영역을 변경하면 작업 영역이 자동으로 업데이트되기 때문입니다. 저장된 작업 공간으로 돌아가려면 브라우저에서 해당 파일을 두 번 클릭하세요. 그러면 모든 것이 마지막으로 저장했을 때의 상태로 재설정됩니다. 레이아웃을 변경할 때 "파일 → 현재 작업 공간 저장"을 선택하여 저장된 작업 공간을 업데이트하세요.
노트북 간 코드 공유
노트북에서 많은 분석을 수행해야 하는 경우 노트북이 길어지고 작업하기 어려워질 위험이 있습니다. 하나의 큰 노트북을 만드는 대신 분석을 별도의 노트북으로 분할하는 것이 좋습니다. 한 가지 방법은 데이터를 복제하는 것이지만 이로 인해 데이터가 변경될 때마다 데이터 관리 문제가 발생합니다. 다행히 JupyterLab을 사용하면 한 노트북의 데이터를 다른 노트북과 공유할 수 있습니다.
앞서 커널은 실행을 위해 노트북에서 콘솔로 코드를 전달하는 역할을 담당한다는 것을 배웠습니다. 코드가 완료되면 커널은 출력을 Jupyter Notebook에 다시 반환하여 표시합니다. 따라서 커널은 프로그램이 사용하는 모든 데이터나 기능에 대한 액세스를 제공합니다. 추가 노트북을 노트북 커널에 연결하면 추가 노트북에서 해당 콘텐츠를 사용할 수 있게 됩니다.
이전에 복사한 Python 인구 데이터 목록이 포함된 노트북 에서 셀을 찾고 Population Changes셀 오른쪽 상단에 있는 휴지통 아이콘을 클릭하여 삭제합니다. 이 시점에서 노트북의 커널은 여전히 데이터를 보유합니다. 이 문제를 해결하려면 메뉴에서 "커널 → 커널 다시 시작 → 모든 셀의 출력 지우기"를 선택합니다. 이렇게 하면 노트북이 재설정됩니다. 내용은 계속 포함되지만 출력은 포함되지 않습니다.

이제 calculate_differences() 코드가 포함된 Population Changes 셀을 다시 실행 하고 실패하는지 확인하세요.

역추적 에서 볼 수 있듯이 코드 에서 NameError가 발생하였습니다. 이는 코드에서 더 이상 필요한 population 목록을 찾을 수 없기 때문에 발생합니다. 목록을 지울 때 목록이 커널에서 제거되어 이제 코드에서 알 수 없기 때문입니다.
이 문제를 처리하고 원본 Population Data 노트북과 동일한 데이터 소스를 사용하려면 Population Changes와 함께 사용 중인 Population Data 커널을 공유해야 합니다. Population Changes 노트북을 선택하고 오른쪽 상단에 있는 커널 전환 버튼을 클릭하면 됩니다. 드롭다운에서 다음과 같이 Population Data 커널을 선택합니다.

이제 Population Changes의 모든 셀을 다시 실행하면 모든 것이 이전처럼 작동합니다. population 목록을 한 번 더 사용할 수 있습니다.
원하는 경우 Population Data 노트북의 데이터를 변경하고 두 노트북을 다시 실행하여 실험해 볼 수 있습니다. 그렇다면 공유 커널을 업데이트하기 위해 데이터를 변경한 셀을 다시 실행하는 것을 잊지 마십시오.
노트북 체크포인트
Jupyter Notebook으로 작업하면 모든 변경 사항이 자동으로 저장됩니다. 그러나 노트북을 수동으로 저장할 수도 있습니다. JupyterLab 언어에서는 이를 체크포인트 라고 하며 Windows 및 Linux에서는 Ctrl+S를 사용하고 macOS에서는 Cmd+S를 사용하여 수행합니다 . 다음과 같이 체크포인트 저장 및 생성 아이콘을 클릭할 수도 있습니다 .

새 노트북 파일을 처음 생성하면 JupyterLab은 .ipynb파일 확장자를 가진 파일을 생성합니다. 또한 두 번째 .ipynb 체크포인트 파일도 생성됩니다. 이는 원본 노트북 파일과 동일한 이름으로 시작하며 이름만 -checkpoint추가됩니다. 이 검사점 파일은 .ipynb_checkpoints원본 노트북과 동일한 폴더에 있는 숨겨진 폴더 안에 배치됩니다 .
기본적으로 초기 노트북 파일과 해당 검사점은 비어 있습니다. 노트북에 콘텐츠를 추가하면 원본 노트북 파일이 2분마다 자동으로 저장됩니다. 체크포인트 파일은 그대로 유지됩니다.
체크포인트 파일과 노트북 파일을 업데이트하려면 Windows 또는 Linux의 경우 Ctrl+S , macOS의 경우 Cmd+S를 사용하거나 메뉴에서 "파일 → 노트북 저장을 사용하여 수동 저장"을 수행하면 됩니다. 이렇게 하면 이전 체크포인트를 덮어씁니다. 그런 다음 노트북을 변경하면 JupyterLab은 이를 2분마다 자동 저장하지만 다시 체크포인트는 변경되지 않습니다.
자동 저장은 유용하지만 잘못된 변경 사항도 자동으로 저장된다는 의미입니다. 여기서 체크포인트가 도움이 될 수 있습니다. "파일 → 노트북을 체크포인트로 되돌리기…"를 사용하여 노트북을 마지막 체크포인트로 롤백할 수 있습니다 .
이를 테스트하려면 Population Changes 노트북의 마지막 셀 아래에 새 원시 셀을 추가 하고 텍스트를 입력하세요. 보시다시피 인구는 10년마다 증가했습니다. 원시 셀에는 완전히 서식이 지정되지 않았거나 서식을 지정할 수 없는 텍스트가 포함되어 있습니다. 이제 노트북을 수동으로 저장하여 체크포인트를 업데이트합니다.

다음으로 원시 셀을 두 번 클릭하여 편집하고 이 셀을 다음과 같이 변경합니다. 보시다시피 인구는 10년마다 조금씩 감소했습니다. 2분 이상 기다린 후 저장하지 않고 노트북을 닫고 서버를 종료합니다. 그런 다음 JupyterLab 서버를 다시 한 번 다시 시작합니다. 노트북을 다시 열면 이러한 변경 사항이 그대로 남아 있어야 합니다. 그렇지 않다면 충분히 오래 기다리지 않은 것입니다. 다시 시도해 보세요. 하지만 이번에는 좀 더 인내심을 가지세요.
이제 당신은 이런 변화를 일으키지 않았더라면 좋았을 것을 깨달았습니다. 되돌리려면 "파일 → 노트북을 검사점으로 되돌리기" 메뉴 옵션을 선택합니다. 확인하라는 메시지가 나타나면 빨간색 되돌리기 버튼을 클릭하세요. 이제 변경한 셀을 살펴보세요.
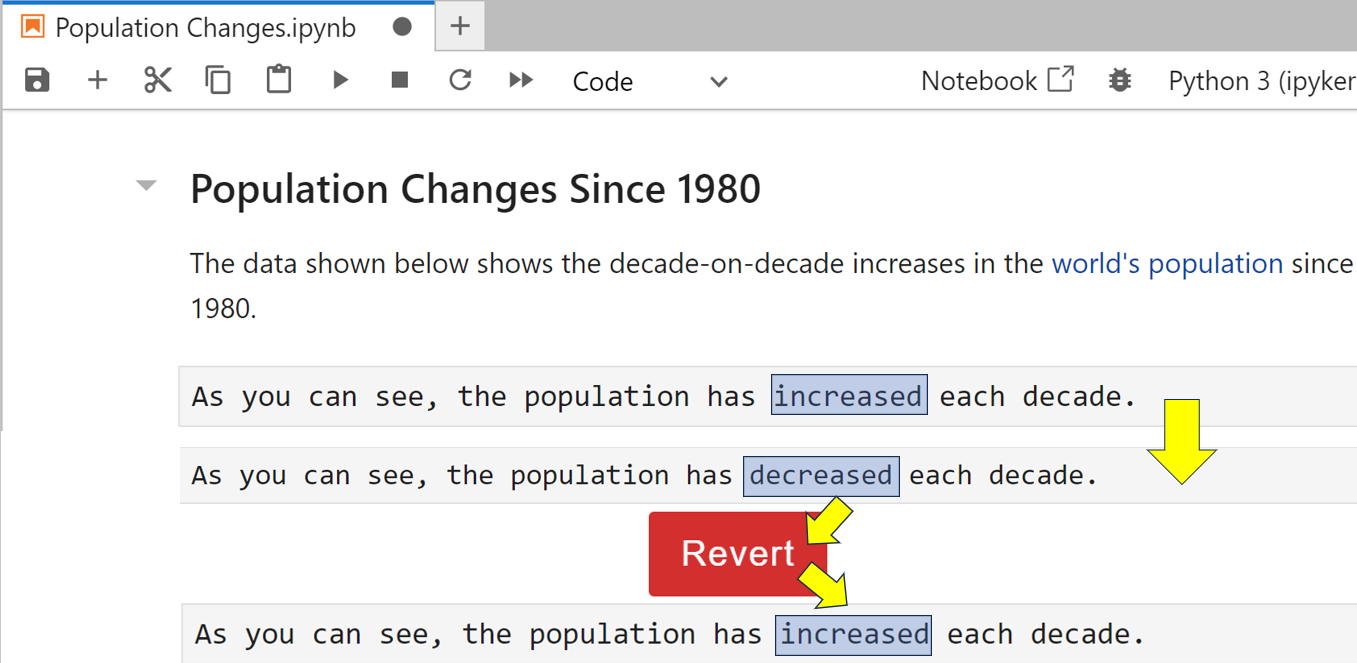
보시다시피, 감소가 증가 로 롤백되었습니다 . 다행히 잘못된 변경사항이 사라졌습니다.
JupyterLab의 체크포인트 기능은 상당히 원시적입니다. 본질적으로 마지막으로 수동으로 저장한 버전으로 되돌릴 수 있는 기능을 제공합니다. 마지막 체크포인트로만 되돌릴 수 있으며, 한 번 되돌린 후에는 더 이상 롤백하거나 다시 롤포워드할 수 없습니다. 수동 저장을 수행하기 전에 변경 사항이 영구 저장해도 안전한지 확인하십시오. 그렇지 않은 경우 이 작업을 취소할 수 없습니다.
노트북을 변경하고 이전 버전을 유지하려는 경우 JupyterLab 내에서 유일한 방법은 "파일 → 노트북을 다른 이름으로 저장"을 사용 하고 각각 약간 다른 파일 이름을 지정하여 각 파일의 여러 버전을 만드는 것입니다. 분명히 이로 인해 여전히 버전 제어 문제가 발생할 수 있습니다.
참고: JupyterLab의 버전 관리 지원이 다소 원시적이라는 점에 실망할 수도 있지만 이를 개선할 수 있는 nbdime 이라는 패키지가 있습니다. 두 노트북 간의 차이점을 강조하거나 병합할 수 있는 도구를 제공합니다. 패키지 이름 nbdime은 실제로 노트북 diff 및 merge 의 약어입니다 .
JupyterLab의 다른 기능 중 일부로 이동하기 전에 노트북 디버깅 방법을 알아보는 것으로 마무리하겠습니다. 이는 이전에 Jupyter 노트북을 사용해 본 적이 있더라도 보지 못했을 수도 있는 것입니다.
노트북 디버깅
JupyterLab은 Jupyter Notebook 이후 버전에 있는 통합 디버거를 사용합니다. 통합 디버거를 사용하면 코드를 한 번에 한 줄씩 실행하여 예상대로 작동하는지 확인하는 등 일반적인 디버깅 작업을 수행할 수 있습니다. 또한 변수 값을 모니터링하여 예상한 내용이 포함되어 있는지 확인할 수도 있습니다.
예를 들어 Population Changes 노트북의 calculate_differences() 함수에 대해 디버거를 실행합니다. 이 함수는 잘 작동하지만 디버거 작동 경험을 얻기 위해 계속 사용할 것입니다.
노트북 내부의 통합 디버거를 활성화하려면 오른쪽 상단에 있는 작은 버그 아이콘을 클릭하세요. 버그가 주황색으로 바뀌면 통합 디버거가 켜져 있음을 나타냅니다.

디버거가 켜져 있으면 화면 오른쪽에 디버거 탭이 선택됩니다. 이는 코드가 실행되는 동안 수행되는 작업을 알려줍니다. 디버거에는 Variables , Callstack 및 Breakpoints 를 포함한 다양한 섹션이 포함되어 있습니다 . 그 중 일부는 이미 확장되어 있지만 여기서는 편의상 모두 축소되어 있습니다. 또한 디버거가 켜져 있으면 각 코드 셀에 줄 번호가 표시됩니다. 디버깅 중에 참조용으로 사용할 수 있습니다.
노트북의 모든 셀을 실행하여 시작하세요. 가장 빠른 방법은 메뉴에서 실행 → 모든 셀 실행을 선택하는 것입니다. 이를 통해 디버거가 노트북의 변수를 표시하는 방법을 배울 수 있습니다.
통합 디버거의 변수 섹션을 확장합니다. 테이블 보기 아이콘을 클릭하면 노트북 코드에서 사용하는 전체 변수 세트와 현재 값이 표시됩니다.

잠시 시간을 내어 화면에 표시된 정보를 살펴보세요. 다양한 목록, DataFrame 및 DataFrame을 생성하는 데 사용한 압축 목록의 내용을 볼 수 있습니다. 이 화면은 디버거를 사용할 때 가장 중요한 화면 중 하나입니다.
디버거가 작동하는 모습을 보려면 먼저 노트북 메모리에서 모든 것을 지웁니다. 이렇게 하려면 "Kernel → Restart Kernel and Clear Outputs From All Cells"를 선택한 다음 Restart 를 클릭해야 합니다.

그러면 노트북의 모든 출력과 변수가 지워집니다. 이제 변수 목록을 보면 모든 변수가 지워진 것을 알 수 있습니다. 각 노트북에는 고유한 커널이 있으므로 각 노트북을 다른 노트북과 독립적으로 지울 수 있습니다. 커널을 다시 시작할 때 디버깅도 비활성화되었습니다.
다음으로 통합 디버거를 사용하는 방법을 알아보기 위해 코드를 디버그해 보겠습니다. 먼저 디버거를 다시 한 번 활성화하고 표시된 대로 Variables , Callstack 및 Breakpointsdecades 섹션을 정렬합니다. 또한 아래와 같이 목록 옆의 여백을 클릭하여 중단점을 설정합니다 .

디버거의 중단점 섹션 에 중단점이 추가된 것을 볼 수 있습니다 . 줄 옆에 작은 빨간색 점이 나타나 중단점이 있음을 나타냅니다. 코드는 중단점까지 정상적으로 실행된 다음 디버그 모드로 들어갑니다. 디버그 모드에 들어가면 원하는 속도로 코드를 실행하여 모니터링할 수 있습니다. 이 경우 첫 번째 줄에 중단점을 만들었으므로 전체 코드가 디버그 모드에서 실행됩니다.
디버깅을 시작하려면 디버깅이 켜져 있는지 확인한 다음 메뉴에서 실행 → 모든 셀 실행을 선택합니다. 코드는 강조 표시된 첫 번째 중단점에서 중지됩니다.

귀하의 노트북 코드는 이제 처리를 일시 중지했으며 다음 진행 방법에 대한 귀하의 지시를 기다리고 있습니다. 선택 사항은 디버그 창의 콜스택 섹션 위 막대에 시각적으로 표시됩니다.

각 아이콘을 클릭하면 프로그램이 약간 다르게 작동합니다. 시작점으로 처음 세 가지 옵션을 고려하세요.
- 계속을 사용하면 두 번째 중단점을 삽입하지 않는 한 셀의 나머지 코드가 정상 속도로 실행됩니다. 이 경우 두 번째 중단점을 삽입하면 정상적으로 해당 중단점까지 실행된 다음 디버그 모드로 다시 들어갑니다.
- Terminate는 셀의 코드 실행을 즉시 중지합니다.
- Next는 다음 코드 줄을 실행한 다음 일시 중지하여 추가 지침을 기다립니다. 이는 전체 프로그램을 한 번에 한 줄씩 실행하여 각 변수가 채워질 때 변수 섹션을 자동으로 업데이트하는 방법입니다. 이는 코드를 디버깅할 때 사용하는 가장 일반적인 작업 중 하나입니다.
디버거를 더 잘 이해하려면 노트북이 여전히 지침을 기다리고 있는 상태에서 다음을 선택 하거나 F10을 탭합니다. 코드는 다음 줄로 진행되고 한 번 더 일시 중지됩니다.

오른쪽의 변수 섹션에 특히 주의를 기울이면 이제 decades 변수에 일부 데이터가 할당된 것을 볼 수 있습니다. 이는 6번 라인이 성공적으로 실행되었기 때문에 발생했습니다. 이 정보를 기록하면 이 코드 줄이 예상대로 작동하는지 확인할 수 있습니다.
이제 F10을 한 번 더 탭하세요. 예상한 대로 이제 population 변수에 데이터가 포함됩니다. 프로그램이 calculate_differences() 함수가 포함된 다음 셀의 맨 위로 이동한 다음 중지됩니다.
이제 F10을 한 번 더 탭하면 제어 기능이 해당 기능 너머의 첫 번째 줄로 이동합니다. 이는 함수 헤더가 포함된 행만 처리되었기 때문입니다. 함수 본문은 코드에서 호출할 때만 실행될 수 있습니다. 헤더를 처리할 때 이제 코드에서는 함수가 존재한다는 것을 알게 됩니다.
이 시점에서 선택을 할 수 있습니다. 다시 F10을 탭하면 population_variable에 해당 데이터가 할당되고 프로그램이 종료됩니다. 디버거가 calculate_differences() 함수에 들어가서 실행할 것이라고 예상했을 수도 있습니다 . 실제로 이 기능은 실행되었지만 최대 속도로 실행되었습니다. 선택하면 F10이 함수 호출을 포함하여 전체 코드 라인이 최고 속도로 실행됩니다. 이것이 바로 다음 아이콘에 점 위로 점프하는 화살표가 있는 이유입니다.
변수 목록을 보면 이제 population_change가 내용이 있음을 알 수 있으므로 함수가 실제로 실행되었는지 확인할 수 있습니다.

보시다시피 이제 인구 변화가 population_change 목록에 표시됩니다.
물론, 함수 코드를 통해 디버거를 실행해야 할 때도 있을 것입니다. 이렇게 하려면 콜스택 섹션에서 종료 버튼을 누르거나 Shift+F9 를 사용하세요. 그러면 디버거가 중지됩니다. 이제 디버거를 다시 시작하고 노트북이 함수 호출 라인에서 중지될 때까지 이전 지침을 반복합니다. 거기에 도달하려면 F10을 세 번 탭해야 합니다.
이번에는 F10, 탭 F11 를 사용하는 대신 호출 스택 섹션에서 Step In 옵션을 하거나 선택합니다. 이름과 아이콘에서 알 수 있듯이 함수 본문을 입력하면 코드로 이동됩니다.

보시다시피, 이제 디버거를 사용하여 함수 코드를 단계별로 실행할 수 있으며 함수 본문의 첫 번째 줄에서 중지되었습니다. 함수 내에만 존재하는 data_set변수에는 이제 데이터가 포함됩니다. 또한 콜스택은 프로그램 제어가 메인 모듈의 7번 라인을 떠나 calculate_differences() 함수에 있는 2번 라인으로 진입했음을 알려줍니다. 이 정보를 통해 프로그램의 흐름을 모니터링할 수 있습니다.
루프를 한 번 이상 반복할 때까지 몇 번 더 F10을 탭하세요. 변수 섹션을 계속 주시하면 루프가 반복됨에 따라 변수가 변경되는 것을 볼 수 있습니다. 원한다면 다시 한번 전체 함수를 한 번에 한 줄씩 실행할 수도 있습니다.
함수가 올바르게 작동한다고 만족하면 Step Out 버튼을 누르거나 Shift+F11를 사용하여 함수의 나머지 부분을 일반 속도로 실행하고 호출한 7번 라인으로 다시 이동할 수 있습니다. 한 번 더 F10을 탭하면 이 마지막 코드 줄이 실행되어 셀이 완성됩니다.
디버거가 켜져 있고 중단점을 설정하지 않은 경우 코드를 실행하면 코드가 정상 속도로 실행됩니다. 그러나 디버그 창에는 여전히 모든 변수의 값이 포함됩니다. 이는 프로그램이 인쇄하지 않고 저장하는 값을 확인하려는 경우 유용할 수 있습니다.
마지막으로 빨간색 원을 클릭하여 개별 중단점을 제거할 수 있습니다. 모든 중단점을 끄는 가장 빠른 방법은 빨간색 버그 기호를 클릭하여 디버깅을 끈 다음 다시 클릭하여 디버깅을 다시 켜는 것입니다.
노트북은 JupyterLab에서 가장 일반적으로 사용되는 구성 요소이지만 유일한 구성 요소는 아닙니다. 이제 다른 흥미로운 기능 중 일부에 주목하게 될 것입니다.
'python > intermediate' 카테고리의 다른 글
| Python 코드 문서화: 전체 가이드 (0) | 2024.02.03 |
|---|---|
| 향상된 노트북 경험을 위한 JupyterLab II (0) | 2024.02.02 |
| Python의 배열-숫자 데이터를 효율적으로 사용하기 II (1) | 2024.01.31 |
| Python의 배열-숫자 데이터를 효율적으로 사용하기 I (1) | 2024.01.30 |
| Python 이름의 단일 및 이중 밑줄 II (1) | 2024.01.29 |