2024. 4. 18. 20:01ㆍpython/intermediate
3단계: Neo4j 그래프 데이터베이스 설정
2단계 에서 본 것처럼 병원 시스템 데이터는 현재 CSV 파일에 저장되어 있습니다. 챗봇을 구축하기 전에 챗봇이 쿼리할 수 있는 데이터베이스에 이 데이터를 저장해야 합니다. 이를 위해 Neo4j AuraDB를 사용합니다.
Neo4j AuraDB 인스턴스를 설정하는 방법을 배우기 전에 그래프 데이터베이스에 대한 개요를 살펴보고 이 프로젝트에서 그래프 데이터베이스를 사용하는 것이 관계형 데이터베이스보다 더 나은 선택일 수 있는 이유를 확인하게 됩니다.
그래프 데이터베이스의 간략한 개요
Neo4j와 같은 그래프 데이터베이스는 저장된 데이터를 그래프로 표현하고 처리하도록 설계된 데이터베이스입니다. 그래프 데이터는 노드, 가장자리 또는 관계, 속성으로 구성됩니다. 노드는 엔터티를 나타내고 관계는 엔터티를 연결하며 속성은 노드와 관계에 대한 추가 메타데이터를 제공합니다.
예를 들어 병원 시스템 노드와 관계를 그래프로 표현하는 방법은 다음과 같습니다.
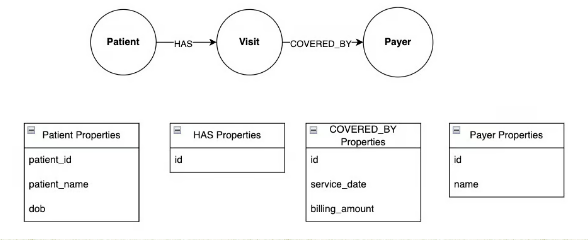
이 그래프에는 환자, 방문 및 지불인이라는 세 개의 노드가 있습니다. 환자와 방문은 HAS 관계 로 연결되어 병원 환자가 방문했음을 나타냅니다. 마찬가지로 방문과 지불인은 COVERED_BY 관계 로 연결되어 보험 지불인이 병원 방문을 보장함을 나타냅니다.
관계가 방향을 나타내는 화살표로 어떻게 표시되는지 확인하세요. 예를 들어, HAS 관계의 방향 은 환자가 방문할 수 있지만 방문에는 환자가 있을 수 없음을 나타냅니다.
노드와 관계 모두 속성을 가질 수 있습니다. 이 예에서 환자 노드에는 ID, 이름 및 생년월일 속성이 있고 COVERED_BY 관계에는 서비스 날짜 및 청구 금액 속성이 있습니다. 이와 같은 그래프에 데이터를 저장하면 다음과 같은 몇 가지 장점이 있습니다.
- 단순성 : 엔터티간의 실제 관계를 모델링하는 것은 그래프 데이터베이스에서 자연스러운 일이므로 쿼리에 응답하기 위해 여러 조인 작업이 필요한 복잡한 스키마의 필요성이 줄어듭니다.
- 관계 : 그래프 데이터베이스는 복잡한 관계를 처리하는 데 탁월합니다. 관계 탐색이 효율적이므로 연결된 데이터를 쉽게 쿼리하고 분석할 수 있습니다.
- 유연성 : 그래프 데이터베이스는 스키마가 없으므로 변화하는 데이터 구조에 쉽게 적응할 수 있습니다. 이러한 유연성은 데이터 모델을 발전시키는 데 도움이 됩니다.
- 성능 : 연결된 데이터 검색은 관계형 데이터베이스보다 그래프 데이터베이스에서 더 빠릅니다. 특히 여러 관계가 포함된 복잡한 쿼리와 관련된 시나리오의 경우 더욱 그렇습니다.
- 패턴 매칭 : 그래프 데이터베이스는 강력한 패턴 매칭 쿼리를 지원하여 데이터 내의 특정 구조를 더 쉽게 표현하고 찾을 수 있습니다.
복잡한 관계가 많은 데이터가 있는 경우 그래프 데이터베이스의 단순성과 유연성 덕분에 관계형 데이터베이스에 비해 디자인하고 쿼리하기가 더 쉽습니다. 나중에 살펴보겠지만 그래프 데이터베이스 쿼리에서 관계를 지정하는 것은 간결하며 복잡한 연결을 포함하지 않습니다. 관심이 있으시다면 Neo4j의 문서에 현실적인 예제 데이터베이스를 통해 이를 잘 설명하고 있습니다.
이러한 간결한 데이터 표현으로 인해 LLM이 그래프 데이터베이스 쿼리를 생성할 때 오류가 발생할 여지가 줄어듭니다. 이는 그래프 데이터베이스의 노드, 관계 및 속성에 대해서만 LLM에 알리면 되기 때문입니다. 이는 LLM이 데이터베이스 전체에서 테이블 스키마 및 외래 키 관계에 대한 지식을 탐색하고 유지해야 하는 관계형 데이터베이스와 대조되어 SQL 생성 시 오류가 발생할 여지가 더 많습니다.
다음으로 Neo4j AuraDB 인스턴스를 설정하여 그래프 데이터베이스 작업을 시작합니다. 그런 다음 병원 시스템을 Neo4j 인스턴스로 이동하고 쿼리하는 방법을 알아봅니다.
Neo4j 계정 및 AuraDB 인스턴스 생성
Neo4j 사용을 시작하려면 무료 Neo4j AuraDB(https://neo4j.com/cloud/aura-free/) 계정을 만들 수 있습니다. 랜딩 페이지는 다음과 같아야 합니다.

무료 시작 버튼을 클릭 하고 계정을 만드세요. 로그인하면 Neo4j Aura 콘솔이 표시됩니다.

새 인스턴스를 클릭 하고 무료 인스턴스를 생성합니다. 다음과 유사한 모달이 나타납니다.

다운로드 및 계속을 클릭하면 인스턴스가 생성되고 Neo4j 데이터베이스 자격 증명이 포함된 텍스트 파일이 다운로드되어야 합니다. 인스턴스가 생성되면 상태가 Running으로 표시됩니다. 아직 노드나 관계가 없어야 합니다.

다음으로, Neo4j 자격 증명으로 다운로드한 텍스트 파일(Neo4j*.txt)을 열고 NEO4J_URI, NEO4J_USERNAME및 NEO4J_PASSWORD를 .env 파일에 복사 합니다.
# .env
OPENAI_API_KEY=<YOUR_OPENAI_API_KEY>
NEO4J_URI=<YOUR_NEO4J_URI>
NEO4J_USERNAME=<YOUR_NEO4J_URI>
NEO4J_PASSWORD=<YOUR_NEO4J_PASSWORD>
챗봇이 쿼리를 실행할 수 있도록 이러한 환경 변수를 사용하여 Python의 Neo4j 인스턴스에 연결합니다.
참고 : 기본적으로 NEO4J_URI 는 neo4j+s://.databases.neo4j.io와 유사해야 합니다. . URL 구성표 neo4j+s는 CA 서명 인증서만 사용하므로 사용자에게 적합하지 않을 수 있습니다. 이 경우 neo4j+ssc URL 구성표(neo4j+ssc://.databases.neo4j.io)를 사용하도록 URI를 변경하십시오. 연결 프로토콜 및 보안 에 대한 Neo4j 문서에서 이것이 무엇을 의미하는지 자세히 알아볼 수 있습니다.
이제 Neo4j 인스턴스와 상호 작용할 수 있는 모든 것이 준비되었습니다. 다음으로 병원 시스템 그래프 데이터베이스를 디자인합니다. 이는 병원 엔터티가 어떻게 관련되어 있는지 알려주고 실행할 수 있는 쿼리 종류를 알려줍니다.
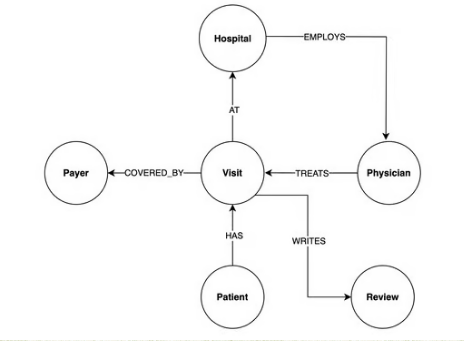
이 다이어그램은 병원 시스템 데이터의 모든 노드와 관계를 보여줍니다. 이 순서도에 대해 생각하는 한 가지 유용한 방법은 환자 노드에서 시작하여 관계를 따르는 것입니다. 환자가 병원을 방문 하고 병원은 보험금 지급인이 보장 하는 방문 치료를 위해 의사를 고용 합니다.
각 노드에 저장된 속성은 다음과 같습니다.

이러한 속성의 대부분은 2단계에서 탐색한 필드에서 직접 가져옵니다. 주목할만한 차이점 중 하나는 검토 노드에 환자_이름, 의사_이름 및 텍스트 속성의 벡터 표현인 임베딩 속성이 있다는 것입니다. 이를 통해 ChromaDB에서 했던 것처럼 리뷰 노드에 대해 벡터 검색을 수행할 수 있습니다.
관계 속성은 다음과 같습니다.

보시다시피 COVERED_BY는 id 속성 이상의 유일한 관계입니다. service_date는 환자가 방문 후 퇴원한 날짜이고, billing_amount는 방문에 대해 지불인에게 청구되는 금액입니다.
참고 : 이 가짜 병원 시스템 데이터에는 기업 환경에서 일반적으로 볼 수 있는 것보다 상대적으로 적은 수의 노드와 관계가 있습니다. 그러나 실제 병원 시스템에 얼마나 많은 노드와 관계를 추가할 수 있는지 쉽게 상상할 수 있습니다. 예를 들어 간호사, 약사, 약국, 처방약, 수술, 환자 친척 및 더 많은 병원 엔터티가 노드로 표시될 수 있습니다.
진단 및 증상이 속성 대신 노드로 표시되도록 이를 다시 디자인하거나 더 많은 관계 속성을 추가할 수도 있습니다. 이미 가지고 있는 디자인을 변경하지 않고도 이 모든 작업을 수행할 수 있습니다. 이것이 그래프의 장점입니다. 데이터가 발전함에 따라 더 많은 노드와 관계를 추가하기만 하면 됩니다.
이제 사용할 병원 시스템 설계에 대한 개요를 살펴보았으므로 이제 데이터를 Neo4j로 이동할 차례입니다!
Neo4j에 데이터 업로드
Neo4j 인스턴스를 실행하고 저장하려는 노드, 속성 및 관계를 이해하면 병원 시스템 데이터를 Neo4j로 이동할 수 있습니다. 이를 위해 몇 개의 빈 파일이 포함된 hospital_neo4j_etl 폴더를 만듭니다. 또한 프로젝트의 루트 디렉터리에 docker-compose.yml 파일을 생성할 수도 있습니다.

.env 파일에는 다음 환경 변수가 있어야 합니다.
# .env
OPENAI_API_KEY=<YOUR_OPENAI_API_KEY>
NEO4J_URI=<YOUR_NEO4J_URI> NEO4J_USERNAME=<YOUR_NEO4J_URI> NEO4J_PASSWORD=<YOUR_NEO4J_PASSWORD>
HOSPITALS_CSV_PATH=https://raw.githubusercontent.com/hfhoffman1144/langchain_neo4j_rag_app/main/data/hospitals.csv PAYERS_CSV_PATH=https://raw.githubusercontent.com/hfhoffman1144/langchain_neo4j_rag_app/main/data/payers.csv PHYSICIANS_CSV_PATH=https://raw.githubusercontent.com/hfhoffman1144/langchain_neo4j_rag_app/main/data/physicians.csv PATIENTS_CSV_PATH=https://raw.githubusercontent.com/hfhoffman1144/langchain_neo4j_rag_app/main/data/patients.csv VISITS_CSV_PATH=https://raw.githubusercontent.com/hfhoffman1144/langchain_neo4j_rag_app/main/data/visits.csv REVIEWS_CSV_PATH=https://raw.githubusercontent.com/hfhoffman1144/langchain_neo4j_rag_app/main/data/reviews.csv
모든 CSV 파일을 GitHub의 공개 위치에 저장했습니다. Neo4j AuraDB 인스턴스는 클라우드에서 실행되기 때문에 로컬 시스템의 파일에 액세스할 수 없으며 HTTP를 사용하거나 파일을 인스턴스에 직접 업로드해야 합니다. 이 예에서는 위의 링크를 사용하거나 데이터를 다른 위치에 업로드할 수 있습니다.
참고: 독점 데이터를 Neo4j에 업로드하는 경우 항상 안전한 위치에 저장되고 적절하게 전송되었는지 확인하세요. 이 프로젝트에 사용된 데이터는 모두 합성된 데이터이며 독점 데이터가 아니므로 공개 HTTP 연결을 통해 업로드하는 데 문제가 없습니다. 그러나 이는 실제로는 좋은 생각이 아닙니다. 해당 설명서에서 Neo4j로 데이터를 가져오는 안전한 방법에 대해 자세히 알아볼 수 있습니다.
.env 파일을 채운 후 TOML 형식으로 정의된 구성, 메타데이터 및 종속성을 제공하는 pyproject.toml를 엽니다.
(참고) 다운로드 받은 화일에 들어 있는 모든 화일을 풀고 source_code_step_3를 카피&paste 하세요.
# TOML hospital_neo4j_etl/pyproject.toml
[project]
name = "hospital_neo4j_etl"
version = "0.1"
dependencies = [
"neo4j==5.14.1",
"retry==0.9.2"
]
[project.optional-dependencies]
dev = ["black", "flake8"]
이 프로젝트는 데이터를 Neo4j로 이동하는 기본 추출, 변환, 로드(ETL) 프로세스 이므로 유일한 종속성은 neo4j 및 retry 입니다. ETL의 주요 스크립트는 hospital_neo4j_etl/src/hospital_bulk_csv_write.py입니다. 여기에 전체 스크립트를 포함하기에는 너무 길지만 hospital_neo4j_etl/src/hospital_bulk_csv_write.py이 실행되는 주요 단계에 대한 느낌을 얻을 수 있습니다. 다운로드 받은 자료에서 전체 스크립트를 복사할 수 있습니다.
먼저 종속성을 가져오고, 환경 변수를 로드하고, 로깅을 구성합니다.
실행 중인 인스턴스에 연결하려면 neo4j에서 GraphDatabase 클래스를 가져옵니다. 여기서는 더 이상 Python-dotenv를 사용하여 환경 변수를 로드하지 않는다는 점에 유의하세요. 대신 스크립트를 실행하는 Docker 컨테이너에 환경 변수를 전달합니다. 다음으로 설계에 따라 병원 데이터를 Neo4j로 이동하는 기능을 정의합니다.
먼저, 각 노드가 고유한 ID를 갖도록 하는 쿼리를 생성하고 실행하는 도우미 함수 _set_uniqueness_constraints()를 정의합니다. load_hospital_graph_from_csv()에서는 Neo4j 인스턴스에 연결하는 드라이버를 인스턴스화하고 각 병원 시스템 노드에 대한 고유성 제약 조건을 설정합니다.
load_hospital_graph_from_csv()에 연결된 @retry 데코레이터를 확인하세요. load_hospital_graph_from_csv()이 어떤 이유로든 실패 하면 데코레이터는 시도 사이에 10초의 지연을 두고 이를 100번 다시 실행합니다. 이는 일반적으로 연결을 다시 생성하여 해결되는 Neo4j에 대한 간헐적인 연결 문제가 있을 때 유용합니다. 그러나 오류가 몇 번 이상 다시 발생하는지 확인하려면 스크립트 로그를 확인하십시오.
다음으로 load_hospital_graph_from_csv()가 각 노드 및 관계에 대한 데이터를 로드합니다.
각 노드와 관계는 그래프 데이터베이스 설계에 따라 해당 csv 파일에서 로드되고 Neo4j에 기록됩니다. 스크립트 끝에서 name-main idiom내의 load_hospital_graph_from_csv()을 호출하면 모든 데이터가 Neo4j 인스턴스에 채워져야 합니다.
hospital_neo4j_etl/src/hospital_bulk_csv_write.py를 작성한 후, Docker 컨테이너가 시작될 때 실행될 entrypoint.sh 파일을 정의할 수 있습니다.
# hospital_neo4j_etl/src/entrypoint.sh
#!/bin/bash
# Run any setup steps or pre-processing tasks here
echo "Running ETL to move hospital data from csvs to Neo4j..."
# Run the ETL script
python hospital_bulk_csv_write.py
이 진입점 파일은 이 프로젝트에 기술적으로 필요하지는 않지만 기본 스크립트를 실행하기 전에 필요한 셸 명령을 실행할 수 있으므로 컨테이너를 빌드할 때 좋은 습관입니다.
ETL용으로 작성할 마지막 파일은 Docker 파일입니다.
# hospital_neo4j_etl/Dockerfile
FROM python:3.11-slim
WORKDIR /app
COPY ./src/ /app
COPY ./pyproject.toml /code/pyproject.toml
RUN pip install /code/.
CMD ["sh", "entrypoint.sh"]
이는 Dockerfile이 컨테이너가 python:3.11-slim 배포판을 사용하고, hospital_neo4j_etl/src/에서 컨테이너 내의 /app 디렉터리에 콘텐츠를 복사하고, pyproject.toml에서 종속성을 설치하고, entrypoint.sh를 실행하도록 지시합니다.
이제 이 프로젝트를 docker-compose.yml에 추가할 수 있습니다.
# docker-compose.yml
version: '3'
services:
hospital_neo4j_etl:
build:
context: ./hospital_neo4j_etl
env_file:
- .env
ETL은 hospital_neo4j_etl이라는 서비스로 실행되며 .env의 환경 변수를 사용하여 ./hospital_neo4j_etl의 Dockerfile을 실행합니다. 컨테이너가 하나뿐이므로 아직 docker-compose가 필요하지 않습니다. 그러나 다음 섹션에서는 ETL을 조정하기 위해 더 많은 컨테이너를 추가하므로 docker-compose.yml를 시작하는 것이 도움이 됩니다.
ETL을 실행하려면 터미널을 열고 다음을 실행하세요.
ETL 실행이 완료되면 Aura 콘솔로 돌아갑니다.

열기를 클릭하면 Neo4j 비밀번호를 입력하라는 메시지가 표시됩니다. 인스턴스에 성공적으로 로그인하면 다음과 유사한 화면이 표시됩니다.

데이터베이스 정보 아래에서 볼 수 있듯이 모든 노드, 관계 및 속성이 로드되었습니다. 21,187개의 노드와 48,259개의 관계가 있습니다. 쿼리 작성을 시작할 준비가 되었습니다!
병원 시스템 그래프 쿼리
챗봇을 구축하기 전에 마지막으로 해야 할 일은 Cypher 구문에 익숙해지는 것입니다. Cypher는 Neo4j의 쿼리 언어이며, 특히 SQL에 익숙하다면 배우기가 상당히 직관적입니다. 이 섹션에서는 기본 사항을 다루며 이것이 챗봇을 구축하는 데 필요한 전부입니다. 보다 포괄적인 Cypher 개요를 보려면 Neo4j의 설명서를 확인하세요.
Cypher에서 데이터를 읽을 때 가장 일반적으로 사용되는 키워드는 MATCH이며, 그래프에서 찾을 패턴을 지정하는 데 사용됩니다. 가장 간단한 패턴은 단일 노드를 사용하는 패턴입니다. 예를 들어 그래프에 기록된 처음 5개의 환자 노드를 찾으려면 다음 Cypher 쿼리를 실행할 수 있습니다.
# 사이퍼 쿼리 언어
MATCH (p:Patient)
RETURN p LIMIT 5;
이 쿼리에서는 Patient 노드를 일치시킵니다. Cypher에서 노드는 항상 괄호로 표시됩니다. (p:Patient)에서 p은 나중에 쿼리에서 참조할 수 있는 별칭입니다. RETURN p LIMIT 5;는 Neo4j에게 5개의 환자 노드만 반환하라고 지시합니다. Neo4j UI에서 이 쿼리를 실행할 수 있으며 결과는 다음과 같습니다.
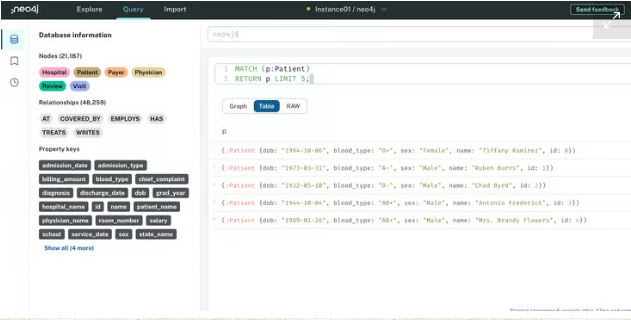
테이블 보기에는 해당 속성과 함께 반환된 5개의 환자 노드가 표시됩니다. 관심이 있는 경우 그래프와 원시 보기를 탐색할 수도 있습니다.
단일 노드에서의 일치는 간단하지만 때로는 유용한 통찰력을 얻는 데 필요한 전부입니다. 예를 들어 이해관계자가 56번 방문에 대한 요약을 제공하라고 하면 다음 쿼리를 통해 답변을 얻을 수 있습니다.
# 사이퍼 쿼리 언어
MATCH (v:Visit)
WHERE v.id = 56
RETURN v;
이 쿼리는 WHERE v.id = 56에서 지정한 56의 id를 가진 Visit 노드와 일치합니다. WHERE절의 임의 노드 및 관계 속성을 필터링할 수 있습니다. 이 쿼리의 결과는 다음과 같습니다.

쿼리 출력에서 반환된 방문의 ID가 56임을 확인할 수 있습니다. 그런 다음 모든 방문 속성을 살펴보고 방문에 대한 구두 요약을 제시할 수 있습니다. 이것이 Cypher 체인이 수행하는 작업입니다.
노드 매칭은 훌륭하지만 Cypher의 진정한 힘은 관계 패턴 매칭 능력에서 비롯됩니다. 이를 통해 그래프 데이터베이스의 강력한 기능을 활용하여 정교한 관계에 대한 통찰력을 얻을 수 있습니다. 계속해서 방문 쿼리를 진행하면서 방문이 어느 환자 에게 속하는지 알고 싶을 것입니다. HAS 관계 에서 이를 얻을 수 있습니다.
# 사이퍼 쿼리 언어
MATCH (p:Patient)-[h:HAS]->(v:Visit)
WHERE v.id = 56
RETURN v,h,p;
이 Cypher 쿼리는 id 56의 Visit를 가진 환자를 검색합니다. 관계 HAS는 괄호 대신 대괄호로 둘러싸여 있고 방향성은 화살표로 표시됩니다. MATCH (p:Patient)<-[h:HAS]-(v:Visit)을 시도하면, HAS 관계의 방향이 올바르지 않기 때문에 쿼리가 아무것도 반환하지 않습니다.
쿼리 결과는 다음과 같습니다.

출력에는 Visit, HAS 관계 및 Patient 에 대한 데이터가 포함되어 있습니다. 이는 방문 노드에서만 일치하는 경우보다 더 많은 통찰력을 제공합니다. 방문 중에 어떤 의사가 환자를 치료했는지 확인하려면 쿼리에 다음 관계를 추가하면 됩니다.
# 사이퍼 쿼리 언어
MATCH (p:Patient)-[h:HAS]->(v:Visit)<-[t:TREATS]-(ph:Physician)
WHERE v.id = 56
RETURN v,p,ph
(p:Patient)-[h:HAS]->(v:Visit)<-[t:TREATS]-(ph:Physician) 명령문은 Neo4j에게 Physician에 의해 처리되는 Visit가 있는 Patient의 모든 패턴을 찾도록 지시합니다. Visit 노드에 들어오고 나가는 모든 관계를 일치시키려면 다음 쿼리를 실행할 수 있습니다.
# 사이퍼 쿼리 언어
MATCH (v:Visit)-[r]-(n)
WHERE v.id = 56
RETURN r,n;
이제 관계 ]에는 (v:Visit) 또는 (n)에 대한 방향이 없습니다. 본질적으로 이 일치 문은 해당 관계에 연결된 노드와 함께 Visit 56에 들어오고 나가는 모든 관계를 찾습니다. 결과는 다음과 같습니다.
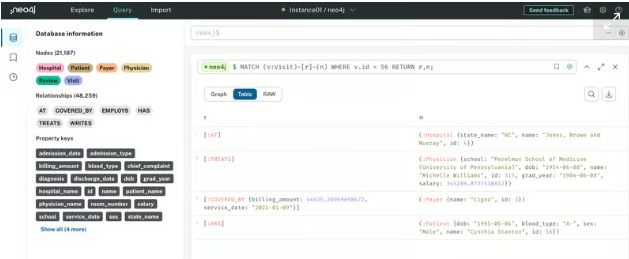
이를 통해 방문 56과 관련된 모든 관계 및 노드에 대한 멋진 보기를 얻을 수 있습니다. 이 표현이 얼마나 강력한지 생각해 보십시오. 관계형 데이터베이스에서 수행해야 하는 것처럼 여러 SQL 조인을 수행하는 대신 짧은 세 줄의 Cypher를 통해 방문이 전체 병원 시스템에 연결되는 방식에 대한 모든 정보를 얻을 수 있습니다.
그래프 데이터베이스에 더 많은 노드와 관계가 추가되면 이것이 얼마나 더 강력해질지 상상할 수 있습니다. 예를 들어 방문과 관련된 간호사, 약국, 약물 또는 수술을 기록할 수 있습니다. 추가하는 각 관계에는 SQL의 또 다른 조인이 필요하지만 방문 56에 대한 위의 Cypher 쿼리는 변경되지 않은 상태로 유지됩니다.
이 섹션에서 마지막으로 다룰 내용은 Cypher에서 집계를 수행하는 방법입니다. 지금까지는 노드와 관계의 원시 데이터만 쿼리했지만 Cypher에서는 집계 통계를 계산할 수도 있습니다.
텍사스에서 Aetna가 보장하는 방문에 대한 총 방문 횟수와 총 청구 금액은 얼마입니까?라는 질문에 대답하고 싶다고 가정해 보겠습니다. 이 질문에 답하는 Cypher 쿼리는 다음과 같습니다.
# 사이퍼 쿼리 언어
MATCH (p:Payer)<-[c:COVERED_BY]-(v:Visit)-[:AT]->(h:Hospital)
WHERE p.name = "Aetna"
AND h.state_name = "TX"
RETURN COUNT(*) as num_visits,
SUM(c.billing_amount) as total_billing_amount;
이 쿼리에서는 먼저 Hospital에서 발생하고 Payer에 의해 포함되는 모든 Visits와 일치시킵니다. 그런 다음 Aetna의 name 속성을 가진 Payers과 TX 의 state_name 속성을 가진 Hospitals을 사용하여 필터링 합니다. 마지막으로 COUNT(*)는 일치하는 패턴 수를 계산하여 총 청구 금액을 SUM(c.billing_amount)으로 알려줍니다. 출력은 다음과 같습니다.

결과에 따르면 이 패턴과 일치하는 방문 수는 198건이며 총 청구 금액은 약 $5,056,439입니다.
이제 Cypher의 기본 사항과 답변할 수 있는 질문의 종류에 대해 확실하게 이해하게 되었습니다. 간단히 말해서 Cypher는 자세한 쿼리를 요구하지 않고도 복잡한 관계를 일치시키는 데 탁월합니다. Neo4j와 Cypher로 할 수 있는 일이 훨씬 더 많지만, 이 섹션에서 얻은 지식은 챗봇 구축을 시작하는 데 충분하며, 이것이 바로 다음에 수행할 작업입니다.
'python > intermediate' 카테고리의 다른 글
| LangChain으로 LLM RAG 챗봇 구축 VII (0) | 2024.04.23 |
|---|---|
| LangChain으로 LLM RAG 챗봇 구축 VI (0) | 2024.04.22 |
| LangChain으로 LLM RAG 챗봇 구축 IV (0) | 2024.04.17 |
| LangChain으로 LLM RAG 챗봇 구축 III (0) | 2024.04.16 |
| LangChain으로 LLM RAG 챗봇 구축 II (0) | 2024.04.15 |